Sự kiện
- Cháy chung cư mini ở Hà Nội
- Vụ cháy chung cư mini 56 người tử vong: Vì sao hơn 110 tỉ đồng hỗ trợ chưa tới nạn nhân?
- Xét xử vụ chuyến bay giải cứu
- Vụ 'Chuyến bay giải cứu': Y án chung thân bị cáo 253 lần nhận hối lộ 42,6 tỉ đồng
- Thi tốt nghiệp THPT 2023
- Tỉ lệ đỗ tốt nghiệp THPT 2023 ở nhiều địa phương đạt gần 100%
- Tấn công trụ sở UBND xã
- Thiếu tướng Đinh Văn Nơi thăm hỏi gia đình các liệt sĩ trong vụ tấn công trụ sở xã ở Đắk Lắk
- Rơi trực thăng Bell-505
- Công ty bảo hiểm lên tiếng về sự cố rơi trực thăng tại Quảng Ninh

Thị trường ô tô điện Việt Nam: Đi nhanh nhưng chưa xa
Với nỗ lực mạnh mẽ của các nhà sản xuất, thị trường ô tô điện tại Việt Nam đã có những bước tiến lớn trong những năm gần đây. Song đánh giá toàn...
.jpg)
Tại buổi họp báo do thành phố Hà Nội tổ chức chiều 28-3, Thiếu tướng Nguyễn Thanh Tùng, Phó Giám đốc Công an thành phố đã thông tin về kết quả điều tra...
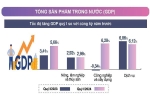
Nền kinh tế nước ta đã đạt nhiều kết quả khá tích cực trong quý I-2024, là nền tảng để hướng tới tăng trưởng cao hơn trong thời gian còn lại của năm.

Không chỉ cho vay lãi nặng, đường dây "tín dụng đen" của anh em nhà họ Thạch do Thạch Anh Quân (tức Quân "trọc") cầm đầu còn tìm cách ép con nợ bán nhà,...

"Hành tinh của chúng ta đang ngập ngụa trong rác thải". Tổng thư ký Liên hợp quốc (LHQ) đã mở đầu như vậy trong thông điệp đưa ra nhân Ngày Quốc tế Không...

Hà Nội là một trong những địa phương đã và đang tích cực triển khai chữ ký số để việc thực hiện thủ tục hành chính, giao dịch điện tử được nhanh...

Lạm phát đo bằng chỉ số giá tiêu dùng cá nhân (PCE) tháng 2 của Mỹ tăng đúng với kỳ vọng ở mức 2,8% cho thấy, lãi suất của Cục Dự trữ Liên bang Mỹ...

Từ đầu năm 2024 đến nay, cả nước đã ghi nhận 6 ổ dịch cúm gia cầm rải rác tại 6 tỉnh, thành phố.

Bộ Giáo dục Trung Quốc vừa phát động chiến dịch tận dụng trí tuệ nhân tạo (AI) thúc đẩy nền giáo dục quốc gia.

Hôm 28-3, Sam Bankman-Fried (32 tuổi) đã bị kết án 25 năm tù vì tội ăn cắp 8 tỷ USD từ khách hàng của sàn giao dịch tiền điện tử FTX do chính anh ta thành lập....

Gần một tuần sau khi Công ty Cổ phần chứng khoán VnDirect bị tấn công vào hệ thống giao dịch trực tuyến (lúc 10h ngày 25-3), khách hàng của VnDirect vẫn chưa...

Được nhận định là giải pháp hiệu quả để đẩy nhanh tiến trình phục hồi của thị trường, các dự án bất động sản phát triển theo hạ tầng giao thông...

Theo Tổng cục thống kê, dự báo tình hình sản xuất kinh doanh quý II-2024 khả quan hơn quý I-2024 với 82% doanh nghiệp đánh giá tốt hơn và giữ ổn định, chỉ 18%...

Hiện nay, có khoảng hơn 5 triệu đối tượng hưởng chính sách an sinh xã hội; đã có gần 1,1 triệu người được chi trả chế độ qua tài khoản.

Lãnh đạo Tổng cục Thuế cho biết, đơn vị này đã và đang tháo gỡ những vướng mắc để người nộp thuế không gặp khó khăn, phiền hà khi chuyển đổi sử...

Năm học 2024 – 2025, Hà Nội có hơn 51.000 học sinh không có chỗ vào trường THPT công lập. Bà Nguyễn Thị Mai Hoa, Phó Chủ nhiệm Ủy ban văn hóa giáo dục của...

Báo cáo Chỉ số giá sinh hoạt theo không gian (SCOLI) năm 2023 của Tổng cục Thống kê mới công bố cho thấy, Hà Nội có mức sống đắt đỏ nhất Việt Nam.

Sau ngày đất nước thống nhất, cùng với các lĩnh vực khác, văn học, nghệ thuật Thủ đô bước vào một chặng đường mới nhiều thách thức song cũng tràn...

Các loại cúm đều có chung những triệu chứng rất khó chịu như cơ thể nhức mỏi, nghẹt mũi khó thở... Dưới đây là một số gia vị hỗ trợ trị nghẹt...

Làn da sáng mịn, mái tóc óng mượt, trái tim khỏe mạnh…là một trong những lợi ích tuyệt vời mà cà chua mang lại cho sức khỏe con người...

Với thành tích phân phối Top đầu nhiều dự án bất động sản tự hào khi tiếp tục được lựa chọn trở thành đơn vị phân phối chính thức Libera Nha Trang -...

Xoang Kim Giao 7 ngày tiêu viêm, 3 ngày hết dịch, thảo dược dịu êm không cay xót hay tái lại. Đây được xem là bài thuốc Nam lành tính, hiệu quả của người...

Ngày 28/3 vừa qua, gần 100 khách hàng là các Tổng thầu EPC, các công ty hoạt động trong lĩnh vực truyền tải năng lượng đã tham dự sự kiện Ngày đối tác...

Mã độc GoldPickaxe, nhắm tới người dùng iPhone ở Việt Nam và Thái Lan, lấy thông tin đăng nhập, gồm cả khuôn mặt, từ đó vượt qua lớp bảo mật sinh trắc...

Chạy bộ là môn thể thao đem lại nhiều lợi ích cho sức khỏe. Tuy nhiên, không phải ai cũng phù hợp với hoạt động này bởi chạy bộ không đúng cách có thể...

Người dân không bắt buộc phải cung cấp ADN, giọng nói khi đi làm thẻ Căn cước từ ngày 01/7/2024.




 97%
97% 27°C
27°C 83%29°C
83%29°C
Cập nhật lúc 04:30:34 26/04/2024(Theo AirVisual)
Ghi chú: Nhóm nhạy cảm bao gồm trẻ em, người già và những người mắc bệnh hô hấp.
Chạy bộ là môn thể thao đem lại nhiều lợi ích cho sức khỏe. Tuy nhiên, không phải ai cũng phù hợp với hoạt động này bởi chạy bộ không đúng cách có thể...
Báo cáo Chỉ số giá sinh hoạt theo không gian (SCOLI) năm 2023 của Tổng cục Thống kê mới công bố cho thấy, Hà Nội có mức sống đắt đỏ nhất Việt Nam.
Không chỉ cho vay lãi nặng, đường dây "tín dụng đen" của anh em nhà họ Thạch do Thạch Anh Quân (tức Quân "trọc") cầm đầu còn tìm cách ép con nợ bán nhà,...

Vào khoảng 17 giờ 45 phút ngày 29-3, Đội Cảnh sát PCCC và Cứu nạn cứu hộ trên sông, Phòng Cảnh sát Phòng cháy, chữa cháy, Công an thành phố Hà Nội bất ngờ...

Hơn 1 triệu người hưởng chính sách an sinh được chi trả qua tài khoản
Hiện nay, có khoảng hơn 5 triệu đối tượng hưởng chính sách an sinh xã hội; đã có gần 1,1 triệu người được chi trả chế độ qua tài...
Hà Nội là một trong những địa phương đã và đang tích cực triển khai chữ ký số để việc thực hiện thủ tục hành chính, giao dịch điện tử được nhanh...

Dù đã được Báo Hànộimới phản ánh nhưng việc tự ý mở đường ngang dân sinh, buôn bán trong hành lang an toàn đường sắt… vẫn diễn biến phức tạp. Đây...
Vào khoảng 17 giờ 45 phút ngày 29-3, Đội Cảnh sát PCCC và Cứu nạn cứu hộ trên sông, Phòng Cảnh sát Phòng cháy, chữa cháy, Công an thành phố Hà Nội bất ngờ...

Tự tay xóa nhòa định kiến người trẻ "dị ứng" với lịch sử, ngày càng nhiều bạn trẻ Gen Z chung tay khơi dậy niềm đam mê tìm hiểu những giá trị truyền...

Theo số liệu tổng hợp của UBND thành phố Hà Nội, trong năm 2024, thành phố sẽ khởi công một loạt công trình giao thông trọng điểm.

Sáng 29-3, tại kỳ họp thứ mười lăm, với 100% đại biểu có mặt tán thành, HĐND thành phố Hà Nội đã thông qua quy định mức giá dịch vụ khám bệnh, chữa...

Sở GTVT Hà Nội đề nghị Cục Đăng kiểm Việt Nam chỉ đạo các trung tâm đăng kiểm từ chối kiểm định cho các phương tiện khi chủ phương tiện chưa chấp...

Luật Đất đai 2024 quy định rõ ngoài các loại đất sử dụng ổn định lâu dài còn có các loại đất loại đất sử dụng có thời hạn. Khi hết hạn, người...

Thủ tướng giao Bộ trưởng Bộ GTVT khẩn trương hoàn thiện, ban hành Quy chuẩn kỹ thuật quốc gia về đường bộ cao tốc, trong đó lưu ý rà soát kỹ, bảo...

Căn nhà phố cổ bị ép bán và hành trình lật mặt nhóm Quân 'trọc' cho vay lãi khét tiếng
Không chỉ cho vay lãi nặng, đường dây "tín dụng đen" của anh em nhà họ Thạch do Thạch Anh Quân (tức Quân "trọc") cầm đầu còn tìm cách ép con...

Nhận cuộc gọi qua zalo video của một nhóm đối tượng giả danh công an, viện kiểm soát nói ông liên quan đến một vụ án rửa tiền và yêu cầu phải chuyển...

Ngày 28/3, ông Bùi Thanh Toàn, Giám đốc Sở Thông tin và Truyền thông tỉnh Bạc Liêu cho biết, thời gian qua, Sở liên tục nhận được phản ánh có dấu hiệu lừa...
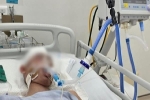
Sau vụ học sinh lớp 8 bị đánh thương tích nặng, cơ quan công an đã khởi tố vụ án, bị can, bắt giam T.V.M (SN 2008) để điều tra về hành vi cố ý gây thương...

Quá trình điều tra truy xét, Công an quận Đống Đa, Hà Nội đã làm rõ và bắt giữ nhóm thanh thiếu niên vác hung khí đi gây rối trật tự công cộng, thông qua...

Cục Đường bộ Việt Nam yêu cầu các Sở GTVT tăng cường sử dụng dữ liệu giám sát hành trình trong quản lý và rà soát từng lần quá tốc độ để xác...

Tối 27-3, Công an thành phố Hà Nội ra thông báo khẳng định, vụ việc xuất phát từ va chạm, mâu thuẫn trong sinh hoạt đời thường nhưng gây hậu quả đáng...

Theo Bộ Công an, việc công khai Kế hoạch tuần tra, kiểm soát, xử lý vi phạm hành chính đang bị một số đối tượng lợi dụng gây khó khăn cho lực lượng CSGT...

Lực lượng quản lý thị trường (QLTT) tỉnh Quảng Ninh kiểm tra, phát hiện 12 cơ sở kinh doanh vàng trên địa bàn tỉnh có vi phạm trong hoạt động kinh doanh vàng.

Cục trưởng Cục QLTT tỉnh Quảng Bình vừa ban hành Quyết định xử phạt vi phạm hành chính đối với Công ty cổ phần Xây lắp và Thương mại Ngân Hà (Hà...

Những lợi ích tuyệt vời của cà chua đối với sức khỏe
Làn da sáng mịn, mái tóc óng mượt, trái tim khỏe mạnh…là một trong những lợi ích tuyệt vời mà cà chua mang lại cho sức khỏe con người...
Mã độc GoldPickaxe, nhắm tới người dùng iPhone ở Việt Nam và Thái Lan, lấy thông tin đăng nhập, gồm cả khuôn mặt, từ đó vượt qua lớp bảo mật sinh trắc...
Chạy bộ là môn thể thao đem lại nhiều lợi ích cho sức khỏe. Tuy nhiên, không phải ai cũng phù hợp với hoạt động này bởi chạy bộ không đúng cách có thể...
Người dân không bắt buộc phải cung cấp ADN, giọng nói khi đi làm thẻ Căn cước từ ngày 01/7/2024.

Vụ tai nạn xảy ra tại quốc lộ 2, đoạn qua huyện Yên Sơn, tỉnh Tuyên Quang sáng nay giữa xe khách giường nằm và xe container khiến 5 người chết, 5 người bị...

Ngày 2/2, một đoạn clip bạo lực gia đình đã được đăng lên mạng xã hội và thu hút được rất nhiều sự quan tâm, chú ý từ phía người xem.

Một bình đựng dầu trong xưởng của đại lý ôtô Toyota bất ngờ phát nổ khiến một người bị thương nặng

Đoạn phim cho thấy một cậu bé quỳ gối trước cửa nhà để cầu nguyện xin cha mẹ ngừng cãi nhau.

Một đoạn video ghi lại khoảnh khắc hai người đang chạy dưới trời mưa và suýt bị sét đánh trúng khiến nhiều người kinh hãi.

Một nữ tài xế lái xe chở theo 4 đứa trẻ và một người lớn đã cố tình băng qua đường ray và bị đoàn tàu tông trúng.

Việt Nam có thêm một trọng tài nữ cấp cao của AFC
Liên đoàn Bóng đá châu Á (AFC) vừa có thư xác nhận Trọng tài Trần Thị Thanh chính thức trở thành trọng tài nữ cấp cao của AFC tiếp theo...

Cựu hậu vệ Dani Alves vừa được tại ngoại sau hơn 1 năm ngồi tù vì tội tấn công tình dục.

Trên trang cá nhân, cựu HLV trưởng đội tuyển Việt Nam - Park Hang-seo đăng dòng trạng thái ẩn ý về sự trở lại của mình sau thời gian "ngủ đông".

Lee Kang-in cúi gập người xin lỗi sau vụ xô xát, cũng như thái độ hỗn hào với đàn anh Son Heung-min ở Asian Cup 2023 vừa qua.

Tiền vệ Jesse Lingard bị chính các cổ động viên nhà Seoul FC phản ứng, vì thái độ tùy tiện và thiếu chuyên nghiệp khi thi đấu tại Hàn Quốc.

Chủ tịch Liên đoàn bóng đá Indonesia (PSSI) Erick Thohir tiết lộ lý do tổ chức trận đấu với tuyển Việt Nam vào khung giờ muộn để có được sự cổ vũ...

Ngày 14-3, tại Hà Nội, Liên đoàn Bóng đá Việt Nam (VFF) công bố Công ty Cổ phần Acecook Việt Nam là nhà tài trợ chính thức của các đội tuyển bóng đá quốc...

Hai năm qua, chiến dịch nhập tịch giúp đội tuyển Indonesia có thêm 10 cầu thủ gốc châu Âu, tuy nhiên, họ cũng bị không ít ứng viên chất lượng, bao gồm thủ...

Ngược dòng đánh bại Man Utd 3-1, Man City đã làm được điều chưa từng thấy ở một trận derby Manchester trong lịch sử Premier League.

HLV Kiatisak Senamuang hết lời khen đội trưởng Nguyễn Quang Hải khi giúp CLB Công an Hà Nội thoát hiểm trước Hà Tĩnh, ở vòng 12 V-League 2023/24.

Đèn tín hiệu dành cho người đi bộ: Hiệu quả chưa như kỳ vọng
Năm 2017, hệ thống đèn tín hiệu tự bấm dành riêng cho người đi bộ được thí điểm lắp đặt tại một số tuyến đường trên địa bàn...

Bất ngờ xảy ra va chạm với xe ô tô khách trên đường Hồ Chí Minh, khiến 2 học sinh đi xe máy tử vong thương tâm.

Xe khách giường nằm biến dạng phần đầu khi bất ngờ tông vào đuôi xe đầu kéo phía trước trên cao tốc TP HCM-Long Thành-Dầu Giây. Hiện chưa rõ thương vong.

Chiếc xe khách chở hơn 30 người chạy theo hướng Bắc - Nam, khi đến địa phận tỉnh Kon Tum thì mất lái, lao xuống vực sâu khoảng 20 mét.

Công an tỉnh Thanh Hóa đang vào cuộc điều tra, làm rõ một vụ tai nạn kinh hoàng trên đường Hồ Chí Minh, khi 2 chiếc xe máy "đấu đầu" nhau khiến 5 người...

Xe khách chở 22 người lao xuống vực sâu trên cao tốc La Sơn - Tuý Loan, đoạn qua TP Đà Nẵng làm 2 người tử vong.

Tai nạn liên hoàn vì tài xế xe tải đâm vào rào chắn độ cao làn đường ưu tiên, làm một xe ô tô 5 đi ngay phía sau không kịp phản xạ cũng lao thẳng vào...

Tin từ Ban An toàn giao thông tỉnh Quảng Ninh cho biết hồi 16 giờ 30 ngày 12-1, tại Km 161, quốc lộ 18, đoạn qua phường Cửa Ông, TP Cẩm Phả xảy ra vụ tai nạn...

Khi đang di chuyển trên Quốc lộ 15, một xe khách chở khoảng 30 người bất ngờ mất lái lao xuống vệ đường. May mắn vụ tai nạn không gây thiệt hại về...

Lực lượng chức năng đang khẩn trương trục vớt và tìm kiếm thi thể tài xế xe tải gặp nạn chìm xuống lòng hồ thủy điện rất sâu

Truyền thông Hàn Quốc: Triều Tiên có thể đang chuẩn bị phóng thêm vệ tinh trinh sát
Truyền thông Hàn Quốc đưa tin, Triều Tiên đang chuẩn bị phóng vệ tinh quân sự thứ 2 từ bãi phóng ở Tây Bắc nước này. Trước đó, Bình...

"Đối với cáo buộc rằng chúng tôi đang lên kế hoạch xâm lược châu Âu sau chiến dịch quân sự ở Ukraine, điều này hoàn toàn vô lý", Tổng thống Nga Vladimir...

Chính quyền Mexico đã giải cứu thêm 16 người khác bị các băng nhóm tội phạm bắt cóc 2 ngày trước đó tại thành phố Culiacan thuộc bang Sinaloa, phía Bắc...

Lực lượng an ninh Pakistan ngày 20-3 đã đẩy lùi một cuộc tấn công của phiến quân vào một khu phức hợp bên ngoài cảng chiến lược Gwadar, khiến 8 tay súng...

Cao ủy Liên minh châu Âu (EU) về chính sách đối ngoại và an ninh Josep Borrell đề xuất chuyển 90% doanh thu tài sản Nga bị phong tỏa ở châu Âu sang một quỹ tài...

Máy bay không người lái (UAV) MQ-9 Reaper của Mỹ hạ cánh khẩn cấp ở Ba Lan sau khi mất liên lạc với trạm điều khiển mặt đất.

Sau khi nhận thông tin về sự xuất hiện của Hamas tại Al-Shifa, Lực lượng phòng vệ Israel (IDF) đã tiến hành đột kích và tiêu diệt một thủ lĩnh cấp cao của...

Nhà lãnh đạo Triều Tiên Kim Jong Un mới đây đã chỉ đạo một cuộc trình diễn quân sự có sự tham gia của các đơn vị xe tăng.

Tổng thống Vladimir Putin hôm thứ Tư tuyên bố Nga đã sẵn sàng về mặt kỹ thuật cho chiến tranh hạt nhân và nếu Mỹ gửi quân tới Ukraine, điều đó sẽ...

Quân đội Mỹ vừa thông báo dỡ bỏ lệnh cấm hoạt động đối với loại máy bay vận tải cánh quạt nghiêng Osprey.

Vết trượt của 'ông trùm' tiền điện tử lẫy lừng nước Mỹ
Hôm 28-3, Sam Bankman-Fried (32 tuổi) đã bị kết án 25 năm tù vì tội ăn cắp 8 tỷ USD từ khách hàng của sàn giao dịch tiền điện tử FTX do chính...
Bộ Giáo dục Trung Quốc vừa phát động chiến dịch tận dụng trí tuệ nhân tạo (AI) thúc đẩy nền giáo dục quốc gia.
Lạm phát đo bằng chỉ số giá tiêu dùng cá nhân (PCE) tháng 2 của Mỹ tăng đúng với kỳ vọng ở mức 2,8% cho thấy, lãi suất của Cục Dự trữ Liên bang Mỹ...
"Hành tinh của chúng ta đang ngập ngụa trong rác thải". Tổng thư ký Liên hợp quốc (LHQ) đã mở đầu như vậy trong thông điệp đưa ra nhân Ngày Quốc tế Không...

Ngày 28/3, người sáng lập sàn giao dịch tiền điện tử FTX Sam Bankman-Fried đã bị kết án 25 tù vì tội lừa đảo khách hàng và các nhà đầu tư trên nền tảng...

Ngày 28/3, Ủy ban điều tra Liên bang Nga cho biết đã bắt giữ một đối tượng bị cáo buộc hỗ trợ tài chính cho những kẻ tấn công nhà hát Crocus City Hall ở...

Ngân hàng Thương mại nhà nước Ethiopia (CBE) đã thu hồi được hơn 3/4 trong số 14 triệu USD khi lỗi phần mềm hồi đầu tháng này cho phép khách hàng rút nhiều...

Việc nộp bản đệ trình tham gia Thủ tục Ý kiến tư vấn của Tòa án Công lý quốc tế (ICJ) về biến đổi khí hậu thêm một lần nữa cho thấy Việt Nam là...

Theo Interpol, các tổ chức tội phạm đứng sau làn sóng các vụ buôn người và lừa đảo qua mạng trong thời kỳ đại dịch và biến Đông Nam Á trở thành một...

Ngày 28-3, theo hãng thông tấn TASS, số người bị thương trong vụ tấn công ở Trung tâm thương mại Crocus City Hall tăng lên 360, trong khi đó, 143 người mất tích

Chuyện siêu hiếm gặp: Người phụ nữ 2 tử cung sinh đôi vào 2 ngày khác nhau
Thế giới vừa chứng kiến một sự kiện hiếm gặp: Một mgười phụ nữ ở bang Alabama - Mỹ sinh hạ một cặp sinh đôi nữ trong 2 ngày khác nhau...

Tưởng chừng như mong manh nhưng một lớp "vỏ sinh học" bí ẩn chính là thứ giúp Vạn Lý Trường Thành bất biến trước thời gian.

Một con chuột khổng lồ cực hiếm lần đầu tiên được máy ảnh của các nhà khoa học ghi lại.

Khi vô tình thất lạc loại quả này, người ta đã phải dựng một con đập tạm để tìm lại cho Từ Hi Thái hậu.

Bốn chữ khắc trên nắp quan tài là gì mà khiến ai đọc xong cũng khiếp sợ?

Lăng mộ Hiếu Mẫn Đế, vị hoàng đế khai sinh triều đại Bắc Chu (557 - 581), được tìm thấy gần TP Hàm Dương, tỉnh Thiểm Tây - Trung Quốc.

Người dân ở vùng đất này sẽ trải qua 65 ngày sống và làm việc mà không nhìn thấy ánh sáng Mặt trời.

Những người thợ đào giếng không ngờ khối đá họ đào lên trông rất tầm thường nhưng lại có giá trị lớn như vậy.

Trong quá trình đào sân để cơi nới ngôi nhà, một người đàn ông Na Uy đã phát hiện một phiến đá lạ, "mở đường" vào ngôi mộ cổ xa hoa của một chiến...

Khi xác con cá nhà táng dạt vào bãi biển, không ai nghĩ rằng một kho báu quý giá ẩn giấu trong ruột của con vật xấu số.

Văn học, nghệ thuật Thủ đô sau ngày đất nước thống nhất: Chuyển mình đầy khát vọng
Sau ngày đất nước thống nhất, cùng với các lĩnh vực khác, văn học, nghệ thuật Thủ đô bước vào một chặng đường mới nhiều thách thức...

Tháng 10-2023, Đà Lạt được UNESCO ghi danh Thành phố sáng tạo âm nhạc. Danh hiệu này đi kèm với những cam kết đầu tư nhằm quảng bá, phát triển âm nhạc...

Chiều qua, đoàn phim "Cái giá của hạnh phúc" đã có buổi ra mắt tại TP. Hồ Chí Minh với đầy đủ dàn diễn viên của phim gồm: NSƯT Công Ninh, NSƯT Hữu Châu, "...

Lễ trao Giải thưởng Cống hiến lần thứ 18, năm 2024 do Báo Thể thao và Văn hóa (Thông tấn xã Việt Nam) tổ chức đã diễn ra tối 27/3 tại Nhà hát Lớn Hà...

Hơn 10 năm sau biến cố nợ nần và gặp phải nhiều vấn đề về sức khỏe, hiện tại nghệ sĩ Phước Sang đang phải nhập viện điều trị tại khoa Tim mạch...

Hai cuộc thi Hoa hậu nộp hồ sơ xin cấp phép tổ chức tại Đà Lạt, Lâm Đồng nhưng bị địa phương này từ chối cấp phép.

Nhân kỷ niệm 70 năm Chiến thắng Điện Biên Phủ, Hãng Phim hoạt hình Việt Nam đang hoàn thành những công đoạn cuối cùng cho 2 bộ phim hoạt hình cắt giấy...

Sau gần 3 năm nỗ lực điều trị phục hồi chức năng kể từ khi không may gặp biến cố về sức khỏe, NSND Công Lý đã dần hồi phục theo hướng tích cực.

Huỳnh Nguyễn Mai Phương được đánh giá là một trong những đại diện xuất sắc nhất của Việt Nam tại đấu trường "Miss World - Hoa hậu Thế giới", đồng...

Trở lại sau 4 năm gián đoạn, "Mr World - Nam vương thế giới" khiến người hâm mộ phấn khích khi đăng tải thông tin trên Fanpage chính thức công bố Việt Nam là...

Giải bài toán thiếu trường THPT công lập ở các thành phố lớn
Năm học 2024 – 2025, Hà Nội có hơn 51.000 học sinh không có chỗ vào trường THPT công lập. Bà Nguyễn Thị Mai Hoa, Phó Chủ nhiệm Ủy ban văn hóa...

Tháng 4-2024, Hà Nội triển khai thí điểm học bạ số tại các cơ sở giáo dục thực hiện chương trình giáo dục phổ thông cấp tiểu học.

Tháng 4-2024, Hà Nội triển khai thí điểm học bạ số tại các cơ sở giáo dục thực hiện chương trình giáo dục phổ thông cấp tiểu học.

Ngày 20/3, Chính phủ ban hành Nghị quyết 32/NQ-CP về Kế hoạch thực hiện Nghị quyết số 686/NQ-UBTVQH15 của Ủy ban Thường vụ Quốc hội giám sát chuyên đề...

Các quận, huyện, thị xã đăng ký phấn đấu có thêm 141 trường đạt chuẩn quốc gia trong năm nay, nhiều hơn 27 trường so với chỉ tiêu thành phố giao.

Tính đến nay, trên cả nước đã có hơn 600 đơn vị tham gia đào tạo y khoa liên tục, tình trạng phát triển tràn lan khiến chất lượng một số cơ sở chưa...

Chính phủ yêu cầu Bộ Giáo dục và Đào tạo chỉ đạo kiểm soát chặt chẽ chi phí xuất bản, phát hành để giảm giá sách giáo khoa, đồng thời nghiên cứu...

Huyện Đan Phượng hiện có tỷ lệ trường đạt chuẩn quốc gia cao nhất thành phố - với 98,2%, nằm trong nhóm 5 đơn vị dẫn đầu thành phố về công tác xây...

UBND thành phố yêu cầu UBND các quận, huyện, thị xã chuẩn bị tốt các điều kiện cho năm học 2024-2025 bảo đảm đáp ứng đủ chỗ học cho học sinh, không...

Trước việc phải ngừng tuyển sinh lớp 6 trong trường THPT chuyên, TP. HCM vừa có phương án đề xuất tách trường Trần Đại Nghĩa thành 2 trường để duy trì...

Những gia vị hỗ trợ điều trị nghẹt mũi, khó thở
Các loại cúm đều có chung những triệu chứng rất khó chịu như cơ thể nhức mỏi, nghẹt mũi khó thở... Dưới đây là một số gia vị hỗ...
Từ đầu năm 2024 đến nay, cả nước đã ghi nhận 6 ổ dịch cúm gia cầm rải rác tại 6 tỉnh, thành phố.

UBND thành phố Hà Nội vừa có kế hoạch thực hiện Chiến lược quốc gia về phòng, chống kháng thuốc giai đoạn 2023-2030, tầm nhìn đến năm 2045 trên địa bàn...
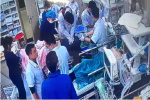
Trên đường về sau ca dạy gia sư, nữ sinh viên 21 tuổi ở Hà Nội gặp tai nạn giao thông nghiêm trọng gây đa chấn thương, vỡ tim… được đưa vào bệnh viện...
Bé gái 7 tuổi ở huyện Đan Phượng là ca mắc rubella đầu tiên trên địa bàn Hà Nội trong năm 2024.

Tại hội nghị trực tuyến liên ngành tăng cường công tác phòng, chống các bệnh lây truyền từ động vật sang người năm 2024 do Bộ Y tế phối hợp với Bộ...

Điều đáng báo động là, mới chưa đầy 3 tháng đầu năm 2024, cả nước có 27 người chết vì bệnh dại, 100.000 người bị chó cắn phải điều trị dự phòng.

Các bác sĩ tại Bệnh viện Đa khoa Massachusetts (Mỹ) cho biết họ đã thực hiện thành công ca ghép thận biến đổi gen đầu tiên trên thế giới từ lợn sang...
Tại Hà Nội, riêng trong năm 2023 phát hiện mới 4.057 bệnh nhân lao, tỷ lệ mắc khoảng 51/100.000 dân, thành phố đang nỗ lực để giảm tỷ lệ mắc và tỷ lệ...

Việc gián đoạn cung ứng các vaccine trong Chương trình tiêm chủng mở rộng năm 2023 làm giảm tỷ lệ tiêm chủng các vaccine cho trẻ em trên toàn quốc, là một...